
How to build AI that feels Intelligent? RAG vs Fine-tuning vs Prompt Engineering
Context Engineering- Part 2

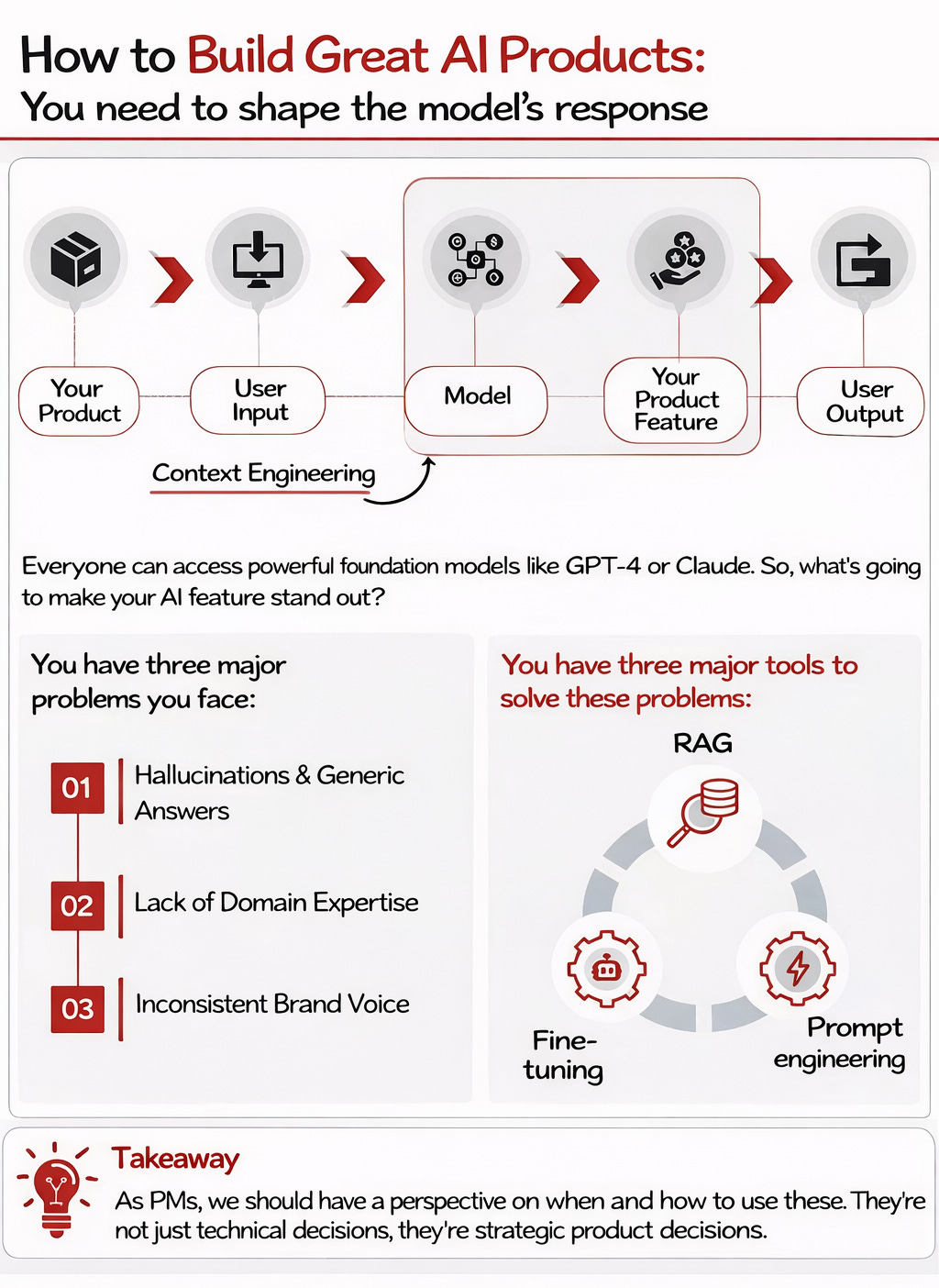
We can all come up with great ideas for LLMs to enhance our products, but the devil is in the details:
How do we get our AI to adopt a very specific writing style?
How do we get our AI to use our latest product documentation?
What’s the fastest way to test an AI concept and get it into users’ hands for feedback?
These aren’t just technical questions. They’re strategic product decisions.
Everyone can access powerful foundation models like GPT-4.5 or Claude Opus 4. So, what’s going to make your AI feature stand out?
Hint: It’s not just about having ‘AI’.
It’s about making that AI uniquely yours and genuinely useful.
Before we dive into these technical execution details, make sure your foundation is solid. I highly recommend starting with How to build AI that feels Intelligent?- Context Engineering Part 1, so you can master the core philosophy before tackling the strategy below.
The 3 Approaches to Optimizing AI
Base LLMs are like brilliant interns: incredibly capable, but they don’t know your company’s specific jargon, your proprietary data, or the nuanced style your customers expect.
Leaving them “off-the-shelf” often leads to:
Hallucinations & Generic Answers
Lack of Domain Expertise
Inconsistent Brand Voice
You have three major ways to address these problems:
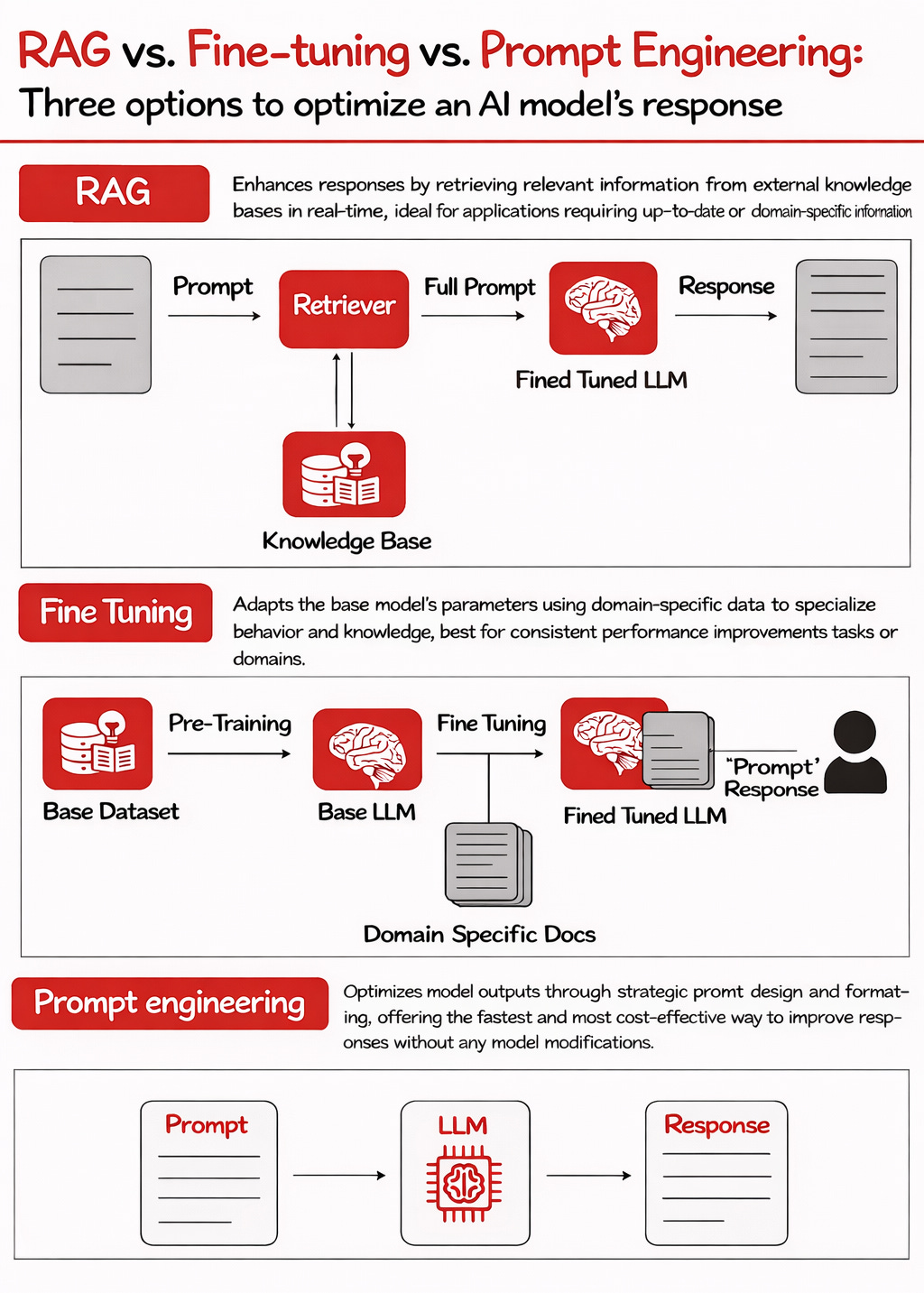
RAG (Retrieval Augmented Generation)
Have a model do a search to enhance its results with information not in its training data set, then incorporate those findings into its answer
Fine-tuning
Specializing a model based on information
Prompt engineering
Better specifying what you’re looking for from the model
The question is: when should you use each, and why?
Today, we’re breaking down the definitive framework for choosing between prompt engineering, RAG, and fine-tuning.
Today’s Post
We’re going to give you the context, decision frameworks, and a practical step-by-step walkthrough to help you build the intuition. Once you build each on your own, you’ll have that AI engineer level knowledge to speak with them confidently:
Mistakes
Pros and Cons
Decision Framework
Think of this post more like a course-lesson where you have to follow along than an article.
TL;DR: Start with prompt engineering (hours/days), escalate to RAG when you need real-time data ($70-1000/month), and only use fine-tuning when you need deep specialization (months + 6x inference costs).1. The 3 Major Mistakes We See
Let’s start by understanding what not to do, then build up to the right approach.
The Strategic Imperative
The truth? There’s a strategic choice between Prompt Engineering, RAG, and Fine-Tuning.
Choosing RIGHT? That’s your path to AI-driven product growth.
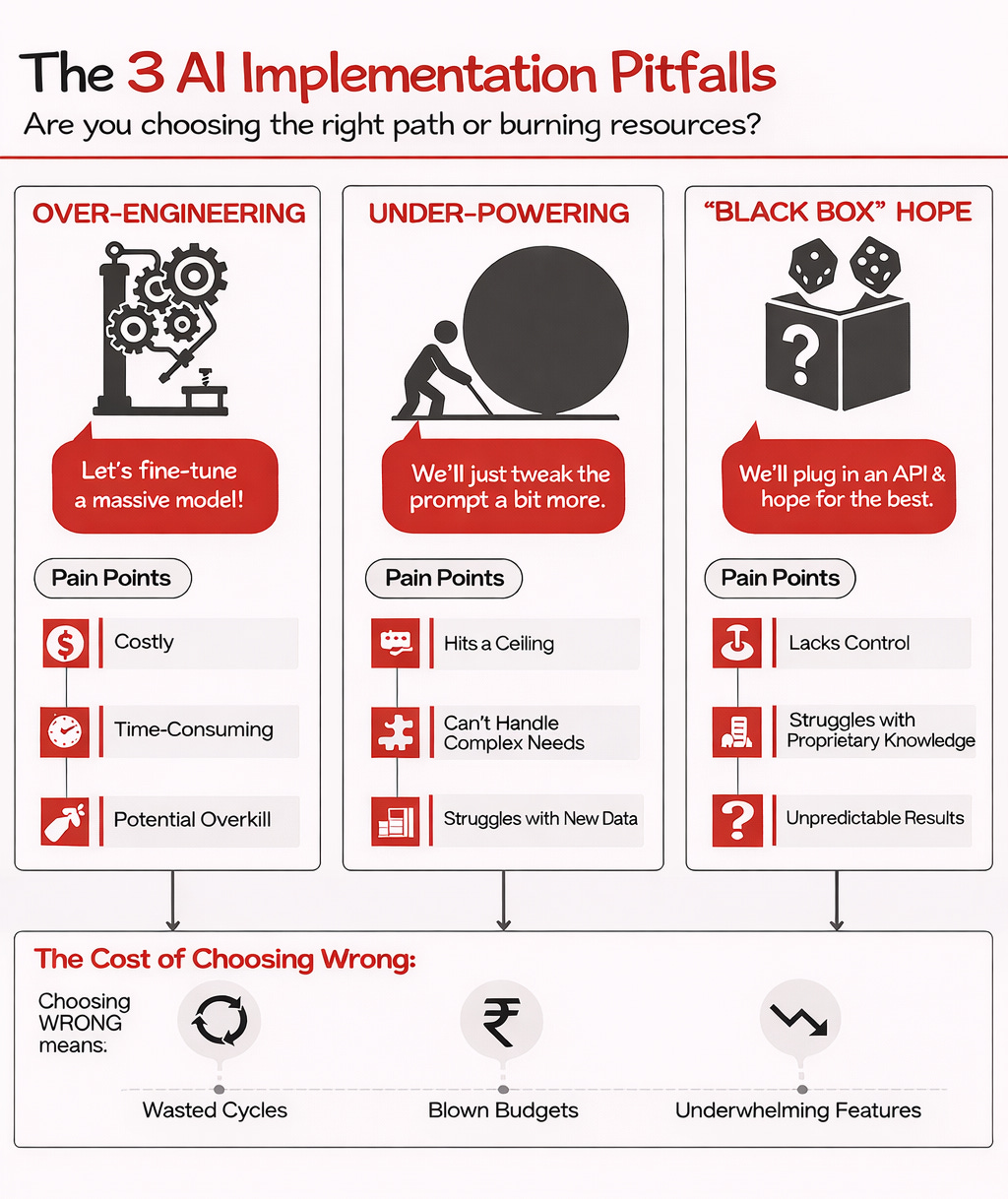
Too often, teams jump to:
Over-engineering: “Let’s fine-tune a massive model!”
(Costly, time-consuming, maybe overkill)
Under-powering: “We’ll just tweak the prompt a bit more.”
(Hits a ceiling, can’t handle complex needs or new data)
The “Black Box” Hope: “We’ll plug in an API and hope for the best.”
(Lacks control, struggles with proprietary knowledge)
The truth is, there’s a strategic choice to be made between Prompt Engineering, Retrieval Augmented Generation (RAG), and Fine-Tuning.
Choosing wrong means wasted cycles, blown budgets, and features that underwhelm.
Choosing right? That’s your path to AI-driven product growth.
This article is your map.
2. Pros and Cons: RAG vs. Fine-tuning vs. Prompt Engineering
Let’s start by understanding each of the three techniques at a deep conceptual level and discuss their pros and cons.
Prompt Engineering
As upcoming podcast guest Hamel Husain says:
Prompt engineering is just prompting these days.
We all have to prompt, but when it comes to building the right prompt for your product feature, prompt engineering is critical.
It goes beyond simple clarification. It’s about transforming the model’s output with additional training or data retrieval. It’s about better activating a model’s existing capabilities.
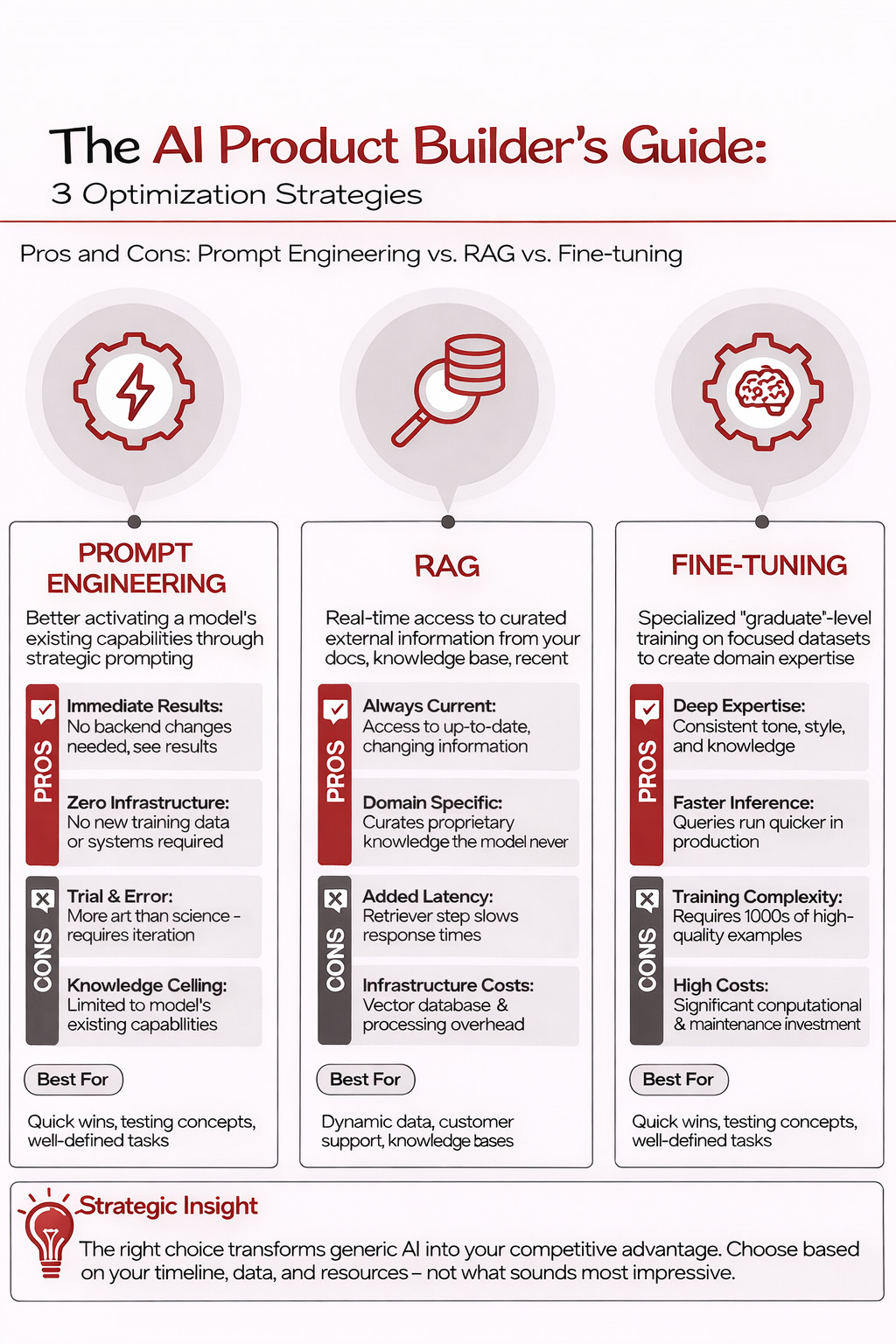
Pros:
You don’t need to change backend infrastructure
You get to see immediate responses and results to what you do - no new training data or data processing required
Cons:
Trial and error - it’s as much an art as a science
You’re limited to the model’s existing knowledge, unable to add new or proprietary data
Fine-tuning
Fine-tuning takes an existing foundation model and gives it specialized ‘graduate-level’ training on a focused dataset relevant to your specific needs.
You’re subtly adjusting the model’s internal ‘weights’ (its understanding of relationships in data) to make it an expert in a particular domain, style, or task.
This typically involves providing hundreds or thousands of high-quality input-output examples.
Pros:
Great when you need deep domain expertise or consistent tone/style
Faster at inference time than RAG because it doesn’t need to search through external data and don’t need to maintain a separate vector database
Cons:
Issues with the training complexity - need 1000s of examples
There are significant computational and maintenance costs involved
You risk “catastrophic forgetting,” where the model loses some general capabilities as it becomes more specialized
RAG
Retrieval Augmented Generation is like giving your LLM real-time access to a specific, curated library of information – your product docs, a knowledge base, recent news, etc.
When a user asks a question, the RAG system first retrieves relevant snippets from this external library and then feeds that context to the LLM along with the original query.
The LLM then uses this fresh, targeted information to generate its answer.
Pros:
Good for up-to-date information
Good for adding domain-specific information
Cons:
Performance impact - retrieval adds latency to each prompt (typically 100-500ms)
Processing costs - eg for the vector database
Ready to add more context to this? We highly recommend staying around for section 4 - where we walk you step-by-step through all 3 so you can have a great addition to your PM portfolio and learn the intuition behind this.
3. Decision Framework
Now comes the million-dollar question: how do you actually decide which one to use, and when?
This is our battle-tested framework after learning from case studies at Shopify, Google, Apollo, and OpenAI:
The Million-Dollar Mistake Most Teams Make
Here’s the uncomfortable truth, the one that burns through budgets and timelines faster than a poorly optimized LLM: Teams reflexively jump to the most complex solution.
Fine-tuning sounds sophisticated, like you’re truly ‘building AI.’
RAG systems feel robust, like you’re tackling data head-on.
So, engineers get excited, data scientists propose intricate architectures, and suddenly, you’re six months deep into a project that could have delivered value in six weeks.
Worst of all? They try to do everything at once.
At Shopify, we’ve seen this play out firsthand with ‘Auto Write,’ their AI content generation feature.
The initial internal buzz was all about fine-tuning GPT-3. Data science was already sketching out a sophisticated RAG system. Everyone had a strong opinion, usually leaning towards the most technically challenging path.
What actually worked? What shipped and delivered value?
They started with disciplined prompt engineering. Simple, direct, and focused.
The result?
They shipped a high-accuracy feature in 10 weeks.
The fancy, more complex approaches like RAG and fine-tuning came later – much later – only after they had validated the core user problem and proven the initial value with the simplest effective method.
The lesson is: don’t let the allure of complexity derail your path to impact.
Our Practical Decision Framework: Your Step-by-Step Guide
How do you avoid the ‘Million-Dollar Mistake’ and make the right call? Here’s the battle-tested decision framework Miqdad and I use:
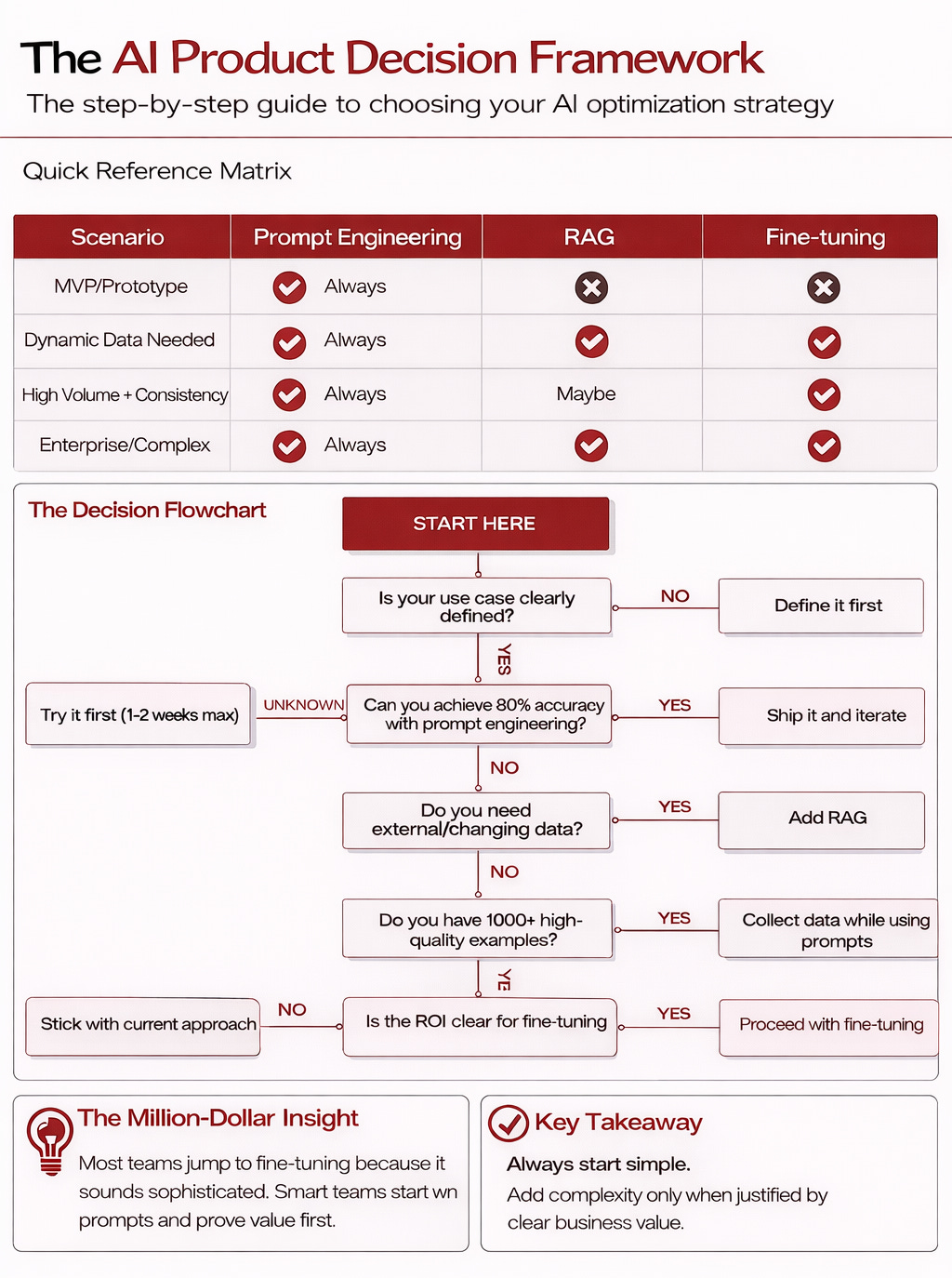
Let’s walk through the logic.
Step 1: Nail Your Use Case
Before you write a single line of code or craft a prompt, ask yourself: Is the user problem you’re aiming to solve with AI crystal clear? Do you know precisely who this is for and what a “win” looks like from their perspective?
Vague goals breed vague AI – features that meander, require endless tweaks, and ultimately, satisfy no one.
“AI for sales” isn’t a strategy; “AI to draft personalized follow-up emails for SMB sales reps based on CRM interaction history” is getting warmer.
If your use case is fuzzy, stop. Seriously. Hammer out the problem definition, user stories, and key success metrics.
This isn’t just a nice-to-have; it’s the non-negotiable foundation. Only once your target is sharp should you proceed.
Step 2: The Prompt Engineering Gauntlet
With a clear use case, your first port of call is always prompt engineering. Can you get to roughly 80% of your desired outcome with well-crafted prompts alone?
This is where you test your MVP or prototype ideas. It’s your fastest, cheapest way to see what the base model is capable of.
Don’t underestimate what good prompting can achieve.
But also, don’t fall into the trap of spending months trying to coax magic out of prompts for a task that fundamentally needs more.
Give yourself a tight timebox – say, one to two weeks max of dedicated effort – to explore this. If you hit that 80% mark, fantastic! Ship it. Get it in front of users, gather feedback, and iterate.
Step 3: The Data Question – Does Your AI Need a Live Feed?
If prompts alone aren’t cutting it, the next question is about data.
Does your AI feature absolutely depend on information the base model couldn’t possibly know? Think: data that changes by the minute, your company’s latest internal product documentation, or user-specific context.
Trying to “teach” an LLM constantly shifting facts through fine-tuning is like trying to fill a leaky bucket – slow and inefficient.
And while prompts can handle small bits of context, they can’t effectively inject vast, ever-changing datasets.
If your AI needs to be current and deeply aware of your specific, evolving world, then RAG (Retrieval Augmented Generation) is your answer.
It gives your LLM a live connection to the knowledge it needs, precisely when it needs it. If external data isn’t the core issue, your challenge likely lies in shaping the model’s inherent behavior or style.
Step 4: The Fine-Tuning Fuel Check – Got Quality Data?
So, prompts weren’t enough, and external data access (RAG) isn’t the primary bottleneck.
You’re now likely looking to instill a very specific style, tone, or a complex, nuanced understanding that goes beyond simple information retrieval.
This is often the case for achieving high volume and consistency in outputs, or for tackling enterprise-level tasks demanding sophisticated pattern recognition.
Welcome to the doorstep of fine-tuning.
But before you step through, check your fuel tank. Do you have at least a thousand (and often many more) high-quality training examples?
These aren’t just any examples; they need to be carefully curated, accurate input-output pairs that perfectly demonstrate the desired behavior you want the model to learn.
Fine-tuning with a handful of examples, or with messy, low-quality data, is a recipe for disaster.
Garbage in, garbage out is brutally amplified here. If you don’t have this data, your immediate focus should be on collecting and curating it, even while you continue to iterate with prompts or RAG.
Step 5: The ROI Litmus Test for Fine-Tuning
You’ve got the data. The need seems clear. But now, the crucial business question: Is the return on investment for fine-tuning undeniably compelling?
Fine-tuning “because we can” or because it sounds impressive on a slide deck is how innovation budgets die a quiet death. The bar should be high.
If the value proposition isn’t screamingly obvious, it’s probably not the right time. Stick with your refined prompt and RAG setup. Re-evaluate later when the case is stronger.
But if the data, the need, and the ROI all align? Then you’ve earned the right to strategically deploy this powerful, resource-intensive technique.
The Core Philosophy: Start Simple, Add Complexity Deliberately
The takeaway here isn’t subtle: Always start with the simplest approach that could work.
Prompt engineering is your first, best friend. Only escalate to RAG or fine-tuning when the problem genuinely demands it, and you can clearly articulate the business case for the added complexity and cost.
Stay tuned for Part 3…